
今回は、私が目標達成AIメンターのアプリを作成する際に挑戦した、OpenAIのFine-Tuningについての話をお届けします。アプリを開発するにあたって、私は特定の書籍データを学習させたカスタマイズモデルを使って、よりパーソナライズされたアドバイスを提供できるAIを目指しました。書籍の内容を理解し、ユーザーに対して最適な助言ができるAIメンターを想像していたのですが、現実は少し違った結果になりました。
Fine-Tuningという手法は、すでにトレーニングされたモデル(例えばGPT-3やGPT-4)に対して、新しいデータを追加して学習させることで、特定のタスクやドメインに特化したモデルを作成することを意味します。いいかると、ある特定領域の専門家のモデルを作成することになります。理論上は、これによりモデルがより深く、特定の分野に精通するはずです。私は、特定の書籍から得られた知識を使って、ユーザーに対して精度の高い回答を提供できると信じていました。
しかし、いざ実際にデータを学習させたモデルを実装してみると、期待していたほどの成果は得られませんでした。モデルは書籍の知識を反映しているはずなのに、なぜか曖昧であったり、的外れで、質の低い回答を返してしまうことが多くありました。結果的に、アプリのリリース時には、通常のGPT-4oモデルを使用する形となりました。
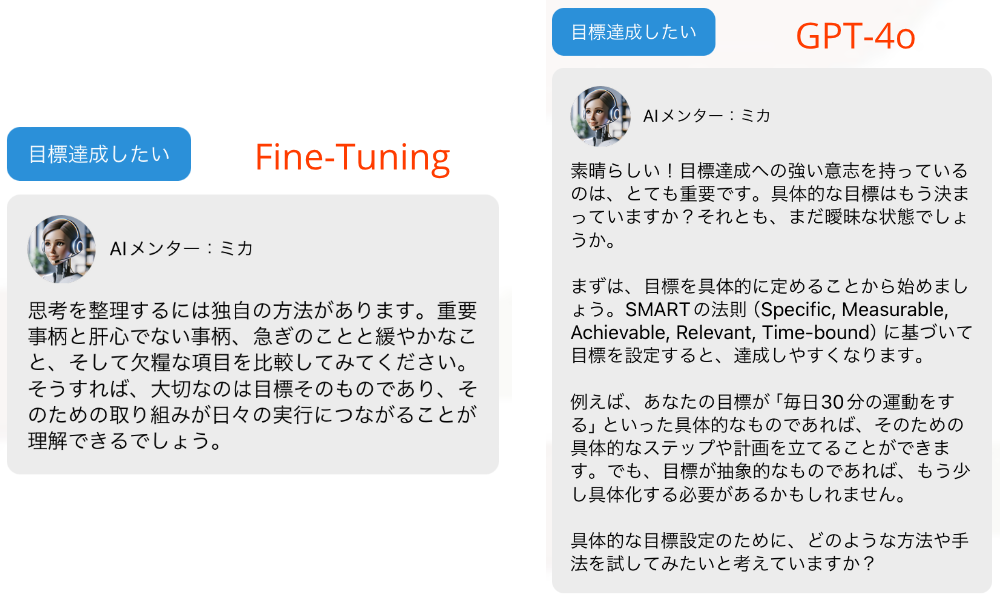
では、具体的にどのように回答精度が違ったのかを、実際の画面で比較してみましょう。左側にFine-Tuningモデルの回答を、右側に通常のGPT-4oの回答を表示します。Fine-Tuningモデルの回答は、書籍から学んだ情報を反映することが期待されていましたが、実際には、求めている具体的なアドバイスを提供できず、よくわからない回答を表示することが多い結果となりました。
これは、ユーザーが「目標達成したい」と質問した場合の実際の解答例ですが、Fine-Tuningモデルは、よくわからない回答をしていることがわかります。これは今回の場合だけでなく、他の入力をした場合でも同様です。一方、通常のGPT-4oは、より広範な知識と柔軟な文脈理解を持っており、Fine-Tuningモデルよりもユーザーの質問に対してより適切な回答を返すことができています。
では、なぜ私のFine-Tuningは失敗したのでしょうか?最大の要因は、私がFine-Tuningのプロセスを過小評価していたことにあります。私は、OpenAIの管理画面から簡単にFine-Tuningができるという情報をもとに、データさえ用意すればすぐに素晴らしい結果が得られると思っていました。しかし、現実はそんなに甘くはありませんでした。
まず、用意した約1,300行のデータは、私が想定していたほどの効果をもたらしませんでした。私が用意した書籍から抽出したデータは、モデルにとって十分に意味のある情報として認識されなかったようです。さらに、1回の学習に1,000円の費用がかかり、結果が出るまでの時間と費用も大きな問題となりました。
この失敗は、私にとって大きな教訓となりました。Fine-Tuningは単にデータを追加するだけではなく、そのデータがモデルにとって適切かどうか、さらにそのデータをどのように処理し、モデルに適用するかが極めて重要であることを痛感しました。
まず、Fine-Tuningを行う際に最も大切なのは、モデルに与えるデータをしっかりと見直すことです。例えば、書籍からデータをそのまま引っ張ってきても、それだけではモデルがその内容を十分に理解できないことがあります。そのため、まずはそのデータが本当に必要な情報だけを含んでいるか、無駄な部分がないかを確認することが重要です。これを「データのクリーニング」と言います。たとえば、長い文章の中から、結論や重要な部分だけを抜き出して、モデルに教えるといった作業です。
次に大事なのは、モデルに教えるデータが一方的なものでないかを確認することです。たとえば、同じ著者の本ばかりを使うと、モデルがその著者の意見に偏ってしまう可能性があります。だからこそ、違う視点や異なる内容のデータも一緒に学習させることが大切です。いろんな意見や情報を取り入れることで、モデルがよりバランスの取れた知識を持つことができます。
さらに、Fine-Tuningを行うときには、モデルがどれくらい勉強するかをしっかりと決める必要があります。ここで言う「勉強」は、どれくらいの期間トレーニングを行うか、どれくらい集中して学習するかを意味します。もし、モデルに過度に勉強させると、特定のデータに固執しすぎて、新しいデータに対応できなくなることがあります。逆に、勉強が足りないと、データをうまく理解できないままになってしまいます。ですので、モデルがバランスよく学べるように、学習の設定を慎重に調整する必要があります。
そして、モデルがちゃんと学んでいるかを常に確認することも大切です。モデルが返す答えを見て、それが期待していたものと違っていたら、どこが悪かったのかをチェックして修正します。これは、まるでテストの答案を見直して、次に向けて改善するようなものです。
最後に、同じような状況で何度も実験を繰り返すことも重要です。モデルに違うデータを教えたり、学習の方法を少し変えてみたりして、その結果を比較します。これにより、どの方法が一番うまくいくかが見えてきます。
Fine-Tuningで良い結果を出すためには、データの選び方やモデルの学習方法を試行錯誤しながら、少しずつ改善していくことが大切といえます。一度で完璧なモデルを作ろうとするのではなく、試行錯誤しながら少しずつ良くしていくことが、成功への鍵です。またトレーニングするとごとに費用がかかるため、費用の確保も重要なポイントとなります。

コメント